Para configurar un proyecto de Spring Batch partiremos con las dependencias que necesitamos utilizando Maven, luego definiremos la configuración basica y algunos aspectos simples para conectarnos a una base de datos embebida.
¿Que es Spring Batch?
Se trata de un framework destinado al proceso de grandes lotes de información. Pero para explicarlo mejor, diremos que con Spring Batch podemos generar trabajos (job) y dividirlos en pasos (steps), como por ejemplo leer datos de una base de datos para procesarlos y luego escribirlos en un archivo.
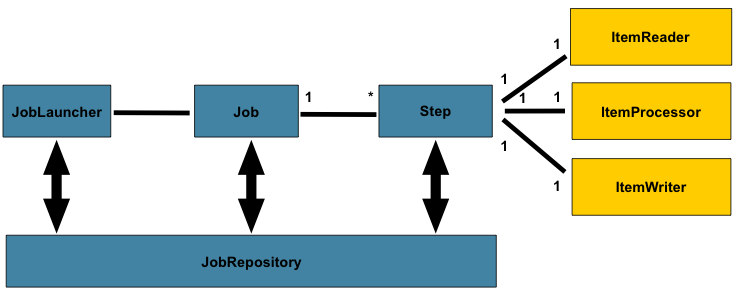
Vemos que un Job puede tener varios Step y cada Step un Reader, un Procesor y un Writer.
¿Qué haremos?
- Conectarnos a una Base de Datos
- Leer todos los registros de una Tabla
- Procesar cada registro modificando el formato de algún dato
- Escribir el resultado en un archivo
¿Que necesitamos?
Lo primero será definir nuestras dependencias. A fin de simplificar haremos uso de spring boot.
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.gp</groupId>
<artifactId>gp</artifactId>
<version>0.1.0</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
</dependency>
</dependencies>
<properties>
<java.version>1.7</java.version>
<!-- The main class to start by executing java -jar -->
<start-class>com.swa.App</start-class>
</properties>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
Definiendo nuestro ItemReader
Este bean utilizará Jdbc con el datasourse definido y la sentencia SQL que necesitamos para realizar la consulta.
También en el reader setearemos un “RowMapper” que como veremos luego se encargará de mapear cada elemento de la consulta en un objeto más entendible para nosotros.
Es decir mapeará el resultSet en nuestro objeto DataIn
@Bean
public ItemReader<DataIn> reader(DataSource dataSource) {
JdbcCursorItemReader reader = new JdbcCursorItemReader();
reader.setDataSource(dataSource);
reader.setRowMapper(new CustomRowMapper());
reader.setSql("SELECT text1, text2 FROM infodata");
return reader;
}
Nuestro RowMapper es así
import com.gp.domain.DataIn;
import org.springframework.jdbc.core.RowMapper;
import java.sql.ResultSet;
import java.sql.SQLException;
public class CustomRowMapper implements RowMapper<DataIn> {
private static final String COLUMN_TEXT1 = "text1";
private static final String COLUMN_TEXT2 = "text2";
@Override
public DataIn mapRow(ResultSet resultSet, int i) throws SQLException {
DataIn data = new DataIn();
data.setText1(resultSet.getString(COLUMN_TEXT1));
data.setText2(resultSet.getString(COLUMN_TEXT2));
return data;
}
}
Definiendo nuestro ItemProcessor
Nuestro ItemProcessor se encargará de recibir un DataIn (que fue creado en el ItemReader) y lo ‘procesará’ haciendo algo de interés para nuestro negocio devolviendo el resultado en otro objeto.
En este ejemplo solo cambiaremos el string a mayúsculas retornando como resultado un nuevo objeto DataOut.
@Bean
public ItemProcessor<DataIn, DataOut> processor() {
return new CustomItemProcessor();
}
import com.gp.domain.DataIn;
import com.gp.domain.DataOut;
import org.springframework.batch.item.ItemProcessor;
public class CustomItemProcessor implements ItemProcessor<DataIn,DataOut> {
@Override
public DataOut process(DataIn item) throws Exception {
DataOut dataOut = new DataOut();
dataOut.setText1(item.getText1().toUpperCase());
dataOut.setText2(item.getText2().toUpperCase());
return dataOut;
}
}
Definiendo nuestro ItemWritter
Para el ItemWriter encargado de escribir el resultado que fue leido (ItemReader) y luego procesado (ItemProcessor) definiremos este bean que guardará el resultado archivo.
Utilizaremos esta implementación que nos provee spring batch FlatFileItemWriter
que se encarga de lo que necesitamos.
FlatFileItemWriter necesita un ‘agregador’ encargado de entender cómo FlatFileItemWriter debe escribir en el archivo.
El agregador que utilizaremos sera DelimitedLineAggregator. Este agregador define el delimitador de cada atributo y tambien cómo debe encontrar la información en el objeto DataOut.
@Bean
public ItemWriter<DataOut> writer() {
FlatFileItemWriter<DataOut> writer = new FlatFileItemWriter<>();
writer.setResource(new ClassPathResource("output.txt"));
DelimitedLineAggregator<DataOut> delLineAgg = new DelimitedLineAggregator<DataOut>();
delLineAgg.setDelimiter(",");
BeanWrapperFieldExtractor<DataOut> fieldExtractor = new BeanWrapperFieldExtractor<>();
fieldExtractor.setNames(new String[] {"text1","text2"});
delLineAgg.setFieldExtractor(fieldExtractor);
writer.setLineAggregator(delLineAgg);
writer.setHeaderCallback(new FlatFileHeaderCallback() {
@Override
public void writeHeader(Writer writer) throws IOException {
writer.write("HEADER");
}
});
writer.setFooterCallback(new FlatFileFooterCallback() {
@Override
public void writeFooter(Writer writer) throws IOException {
writer.write("FOOTER");
}
});
return writer;
}
Configurando nuestro Job
Con nuestro Reader, Processor y nuestro Writer ya podemos configurar nuestro Step y el Job que correrá dicho Step.
Nuestro Step queda así:
@Bean
public Step step1(StepBuilderFactory stepBuilderFactory, ItemReader<DataIn> reader,
ItemWriter<DataOut> writer, ItemProcessor<DataIn, DataOut> processor) {
return stepBuilderFactory.get("step1")
.<DataIn, DataOut> chunk(100)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
Nuestro Job queda de este modo:
@Bean
public Job sqlExecuteJob(JobBuilderFactory jobs, Step step, JobExecutionListener listener) {
Job job = jobs.get("job1")
.incrementer(new RunIdIncrementer())
.listener(listener)
.flow(step)
.end()
.build();
return job;
}
Vemos que en el job hemos hemos agregado además un listener que escuchará la finalización del Job. Para este ejemplo solo imprimimos en el log un mensaje.
@Component
public class JobCompletionNotificationListener extends JobExecutionListenerSupport {
private static final Logger log = LoggerFactory.getLogger(JobCompletionNotificationListener.class);
@Override
public void afterJob(JobExecution jobExecution) {
if(jobExecution.getStatus() == BatchStatus.COMPLETED) {
log.info("!!! JOB FINISHED! Results: ");
}
}
Configurando la Base de Datos
A fin de seguir simplificando dejaremos que Spring boot utilice la base de datos por defecto H2 en memoria. Esto ocurre cuando no le decimos qué base de datos utilizar.
Además spring boot utiliza para crear las tablas algun esquema definido en un archivo .sql
Este archivo lo tenemos en \src\main\resources\schema-all.sql
DROP TABLE infodata IF EXISTS;
CREATE TABLE infodata (
infodata_id BIGINT IDENTITY NOT NULL PRIMARY KEY,
text1 VARCHAR(20),
text2 VARCHAR(20)
);
Spring boot cargará los datos que necesitamos para esta prueba del archivo data.sql
INSERT INTO infodata (text1, text2) VALUES ('text1', 'text11');
INSERT INTO infodata (text1, text2) VALUES ('text2', 'text22');
Ejecutando job:
Desde la consola ejecutaremos mvn spring-boot:run
INFO 6556 --- [.swa.App.main()] o.s.b.c.l.support.SimpleJobLauncher : Job: [FlowJob: [name=job1]] launched with the following parameters: [{}]
INFO 6556 --- [.swa.App.main()] o.s.batch.core.job.SimpleStepHandler : Executing step: [step1]
INFO 6556 --- [.swa.App.main()] c.s.j.JobCompletionNotificationListener : !!! JOB FINISHED! Results:
INFO 6556 --- [.swa.App.main()] o.s.b.c.l.support.SimpleJobLauncher : Job: [FlowJob: [name=job1]] completed with the following parameters: [{}] and the following status: [COMPLETED]
INFO 6556 --- [.swa.App.main()] com.swa.App : Started App in 7.041 seconds (JVM running for 19.432)
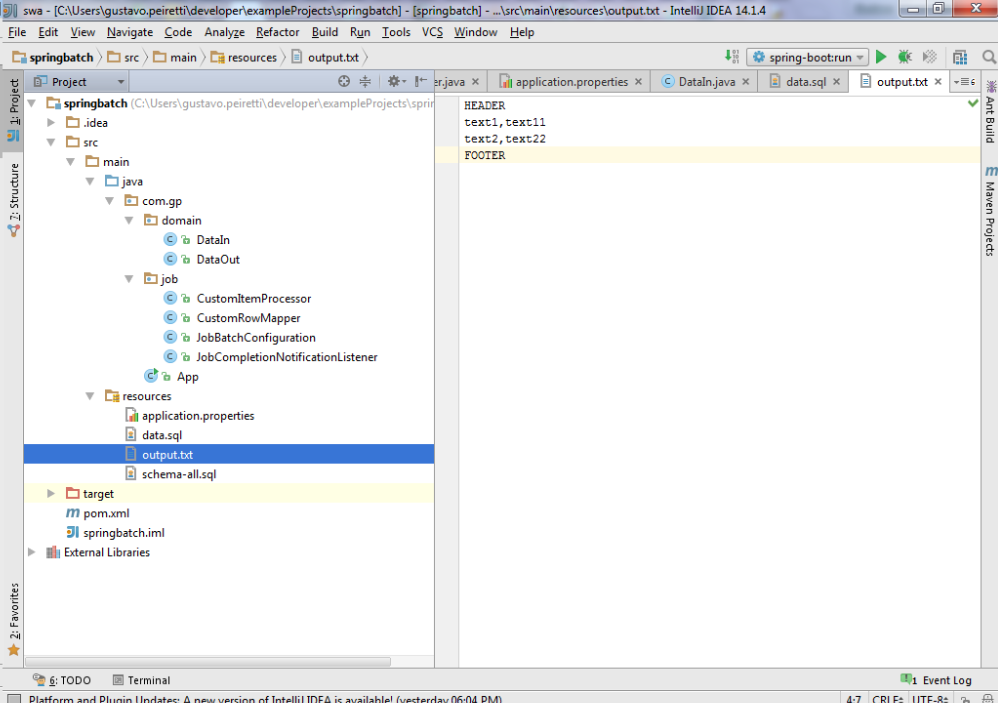
Resultado de nuestro job:
Tal como definimos en el ItemWriter
writer.setResource(new ClassPathResource(“output.txt”));
Deberíamos ver un archivo output.txt en nuestra carpeta resources
Conclusión:
Spring Batch nos provee una herramienta simple y clara para configurar diferentes pasos que comprenden un trabajo que necesitamos ejecutar de forma periódica. Hemos visto con este sencillo ejemplo lo facil que resulta leer datos, procesarlos y escribirlos en alguna salida.
Si sumamos tambien Spring Boot logramos trabajar con convenciones de forma rapida y sin importantes configuraciones.
Descargar Código
Puedes descargar este código desde Aqui
Cualquier consulta o sugerencia es bienvenida